The LPD print protocol is central to RPM Remote Print Manager® (“RPM”). Much of what RPM is about is based on the LPD print protocol.
For instance, in LPD, the commands all relate to a print queue. You submit a job to a queue, get the status of jobs in a queue, remove jobs from a queue, restart a queue. Consequently, queues are central to RPM and other types of print requests, besides LPD, submit their incoming jobs to a queue.
Just before version 6.2, we rolled out an entirely new LPD module. This article describes the philosophy and mechanics of that new module.
Introduction to an LPD print request
An LPD command looks like:
| Command code | Queue name | Line feed |
I’ve looked at the published specifications for many printers. Many printers which support the LPD protocol will recognize the queue name and will process the job differently, depending on the queue name.
In RPM, we put an enormous amount of configuration in each queue so that it handles job requests and produces outputs precisely the way you want.
I have seen some print servers which use the queue name to look up a local printer they will route the jobs to. Most print setups I saw in the Linux world had precise processing which would only work well for an exact data format.
The reason why network probes create random queues in RPM
We typically encounter one of two types of network probes.
The first type sends a print status request to RPM immediately after sending a job. This request goes to the same queue. Depending on how RPM answers this request, the probe marks RPM responsive or unresponsive. So long as it thinks RPM responds, their print system will continue to send jobs. If RPM fails according to their terms, then the print system marks RPM as offline.
We also encounter probes which loads RPM with requests for randomly named queues. These probes can be partial print requests where it says “print a job on this queue” and then drops the connection before it sends a job.
We assume these probes are malicious and for that reason, we have started logging the originating IP address for these requests. The log should help someone in your company track these probes down if they are unwanted.
The RPM message log contains a record of incoming print requests. You can also get a higher level of detail, if you like, by selecting “lpd2” in the diagnostic log.
Auto-create queues or not
I decided to make RPM create queues on the fly for the following reason. In the early days, people would say to me, I set up such and such a queue, but when I started getting print requests from my host system, the jobs didn’t arrive in that queue. Instead, they arrived in a different queue (as if this was a giant misunderstanding on my part). The reason that happened is that someone used a different queue name in the remote setup.
For that reason, it makes sense to me for RPM to auto-create queues.
The second reason is that if RPM doesn’t auto-create queues, then when you create a queue on your remote system and send a test print, RPM will error the request. That is not really what we’d call a time saver.
However, in the early days, network probes were not a problem like they are today. For that reason, it may make sense to leave auto-create turned on while you first set up RPM, then turn it off to avoid making crazy numbers of junk queues.
The additional queues don’t cause a problem in that they use almost no resources or CPU time. I understand why a person would not want to look at all that chaos.
To set the auto-create for LPD go to Configure / Port Settings, then double click on the row with “lpd”:
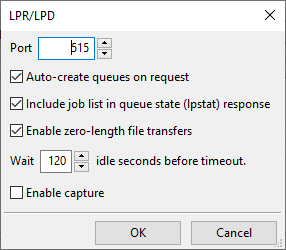
The setting “auto-create queues on request” controls whether RPM creates queues from an incoming request, or not.
Introduction to the control file and metadata
An LPD print request has several components. One of those is a control file. The control file contains, at a minimum, this information:
- Host, which is the computer the print job is from (this is a name selected by the print system)
- User, which is the name associated with this print job
- The job format
- The name of one or more data files (we’ll get to data files below)
RPM looks for a few other key pieces of information in the control file such as:
- Job name
- Title
- Who to email when the job prints
RPM extracts everything it can from the control file, and the job name is vital among these items. You’ll see later when we create the job that the job name is essential, so if we can’t find the job name one way, we’ll keep looking for something to use.
Finally, RPM assembles other information about the job which it tracks, including (but not limited to):
- The data size in bytes
- The time the job was submitted from the remote host, and when it had fully arrived
- The current status of the job, such as it’s waiting for processing, or it’s active or on hold
- Any error status
- The name of the data file or files which are included in this job
- The queue this job is associated with
The control file contains specific data about the job. It is controlled partly by an Internet reference document called RFC1179, and partly by the implementers in the world who understand things their way and produce software others use.
Other implementers dictate to us what they send, and RPM does its best to interpret accurately. That is why we have logging options, so if we get something wrong, we can have some original bytes to understand the data provided to us.
Data files
To talk about data files, we need to first talk about the conversation between the print client and RPM. Rather than boring almost everyone on earth by talking about bytes, I’ll summarize the conversation as follows:
| Print client: | RPM: |
| I want to send a print request for this queue | OK |
| I want to send you a control file, and here’s how big it is | OK |
| Here are the control file bytes as promised | OK |
| I want to send you a data file, and here’s how big it is | OK |
| Here’s the data file | OK |
The process is simple when it happens the way I describe. The only problem is, it doesn’t happen that way.
There are three more likely ways this can go.
1. The sending side can send the correct number of bytes.
2. The sending size can send zero, which is legal although most print clients don’t seem to know about it.
3. The sending side can do it the Microsoft way, where the data file size is over 4 billion. Way over.
We found this out the hard way when customers started reporting to us that they set up a Windows printer port to direct jobs to RPM, and RPM wasn’t able to receive. Our logging showed us what the Microsoft port monitor was sending us.
How we solved the byte counting problem
In a way, it makes sense that Microsoft would tell us to expect an impossibly huge number of bytes. As I understand this setup, it’s the Microsoft port monitor that does this. The port monitor is receiving data bytes from a print driver. At the time the port monitor contacts RPM it has no idea how many bytes the print driver is going to send.
Like I mentioned above, saying you have zero bytes to send is legal, and RPM supports it. You can see the option for “zero length data files” in the LPD setup from above. What I suspect is that many printers or other software solutions don’t support the zero byte option.
I also suspect that other printers or software solutions aren’t hung up on that byte count being accurate. It’s easy for me to imagine that if the actual print job is smaller than promised, many solutions will print what they have. RPM attempts to signal an error when things don’t seem right. However, in the latest edition of the LPD protocol module, I decided that if the “promised size” was over 4 billion and the actual was less, I would roll with it and not signal the error. In this case I assign the actual bytes received to the data size, and move on.
Testing and customer feedback seem to confirm that this approach works.
Stream printing aka the zero byte option
I’ve lost track of this gentleman’s name but some years ago I met someone who had a great deal of expertise in print protocols. He told me that one thing I should support is the zero byte option. If the print client said the data file was going to be zero bytes, I was to respond to that as if it were fine and then receive bytes until the connection closed. No need to look for a match between bytes received, and bytes promised.
The other component of that is that it was possible for the sender to hold the connection open but stop sending bytes. If a timeout period passed, then RPM was to consider the job transfer complete.
You’ll notice we support those options in the LPD setup form. I don’t know how often this comes up, but I’ve tested for it in developing the new protocol module.
Compiling the parts of the print request
The following behavior is a departure from the LPD module we created for RPM version 5, which we used with some updates through version 6.0 and 6.1.
We added a folder called “JOBS” to the RPM data folder where we keep the database and the spooled jobs in the various queues. In the JOBS folder, we create a file for each control file we receive and each data file.
As described above we also keep all the metadata for the job including the time the job arrived, the full path names of the control and data files, and the full text of each command we receive as part of the job. We also store the entire set of job metadata in a text file in the JOBS folder.
Should RPM or your system ever go down, and on startup if RPM finds these files, it will create jobs using this data so that, as much as possible, you will never lose jobs.
Creating the print job or jobs
When we were working on the earlier version of the LPD module that we used in RPM 5.0 and beyond, every time we got a significant bit of data from the print client, we did a database update.
Once, I did some analysis on the database calls I was making while receiving a job; I discovered that the typical job had 8 SQL commands and half of them were redundant.
With the new version of the LPD module, I first assemble all the information about the job, as described above, then make one call to create the job, then anoter to update with metadata. Doing it this way I had roughly four to six times the throughput, that is, jobs created per second over time.
I should mention that each job has a unique job ID and that job creation is a critical operation. We created a database procedure in SQL to make sure that we do the job creation right, every time. After we create the job with a few critical data items, we then add the rest of the metadata as an update.
The current release defers creating jobs to a separate thread. This way, the RPM networking can focus solely on receiving the job and compiling the data on disk. The print client never sees a delay in RPM’s responses due to calls to the database. We have seen a speed increase this way of fifty to ninety times.
Capture files
While we have the diagnostic log for the new LPD object, sometimes it helps to be able to reproduce the print job on our support systems. For this reason, we added an optional “capture” to the new LPD module.
What this means is that we record each command we received. Each separate print job goes into its own capture file.
We decided to NOT include actual print data in the capture. This way we refer to the print data by merely saying we had so many bytes sent to us, not what those bytes were.
I developed a script we use in-house to “replay” the capture files.
I should mention that if you turn on capture, you should do that only as long as you need to, then turn it back off. I turned it on once and forgot about it. A couple of weeks later I started to wonder why RPM was taking so long to start up. I tracked it down to RPM looking at but ignoring 80 thousand capture files in my spool folder.
If it were me, I would create the capture files, email them to our technical support, then delete them. They don’t accomplish anything and RPM doesn’t need them for anything. And turn capture off.
Multiple requests
A typical LPD print request has a single control file and a single data file. LPD supports having a control file refer to more than one data files. RPM, of course, supports this.
It’s also possible to include multiple print jobs in a single print request by having the print client tell RPM “receive a print job on this queue” as we saw above. Then it sends a control file, then a data file, then another control file plus data file, and so on until the client closes the connection.
RPM supports this. In an article on our site about print clients, we mention the rlpr program on Linux systems. If you need to send a lot of files in a hurry, rlpr will get the job done for you.