What it does
The code page conversion translates your print job from one character set, or code page, to another. Another term for character set is data encoding. Typically the characters in a data file will have one data encoding so that a program that reads this file (or a user looking at a document) can interpret the data as it was intended to be.
Setup
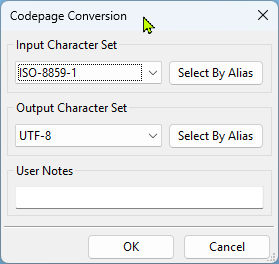
- Input character set: this is the code page for the incoming data.
For example, we tend to see Chinese data. This is typically in Big5 format or Traditional Chinese. In this case, we would select "Big5" as the input character set.
- Output character set: this is the code page or encoding for the result data.
You would have to know what you are looking for in the result data. A vendor really can't recommend what you want here. However, for the sake of example, RPM uses this transform internally in the Text Markup transform. We let the user select the input character set in the Text Markup dialog. Then, RPM automatically selects "UTF-8" as the output character set because it works best for us to use UTF-8 for the text markup.
Examples
A typical example, for us, is translating one of the many EBCDIC variants to ASCII or UTF-8. This article demonstrates how to do that.